Scraping API keys from Repl.it
In 2017 I scraped all publicly available code from repl.it and shared some graphs about the metadata, I was going to share my script to scrape but doing some analysis I found API keys. Since then repl.it changed how code is shared, it can no longer be scraped via enumeration and the old repls susceptible were removed.
The code used to find the API keys is on GitHub: https://github.com/AceLewis/finding-api-keys-on-repl-it
Sections
- What is the repl.it?
- What data do I have, and how did I get it?
- Searching for API keys
- How to reduce the risk
- Final comments
What is the repl.it?
Repl.it is a website for sharing and also executing code from within the browser, 33 languages were supported at the time of the scrape.
What data do I have, and how did I get it?
I have all data of code shared publicly on repl.it from when it started September 2011 until March 2017 in a 1.61 GB CSV file.
I obtained this data because the code shared on repl.it used to have the URL repl.it/XXXX where ‘XXXX’ was 4 letters and/or numbers that incremented e.g after aaaa is aaab then aaac (A-Z0-9a-z). I just wrote a script to enumerate all possible combinations and save the code for every URL. This code is shared on GitHub (code_used_to_scrape_replit.py) but no longer works as all old links have been removed.
Searching for API keys
Back in 2017 I was planning to share the code I used to scrape the data (code_used_to_scrape_replit.py) but when looking at it I found API keys, these were probably still active so I decided against this and just made some graphs about the code that was on repl.it.
Now repl.it does not save code using an auto-incrementing system and all URLs using the old format return a 404 e.g https://repl.it/GFlg. People are no longer able to obtain this data so it is safe to publish online.
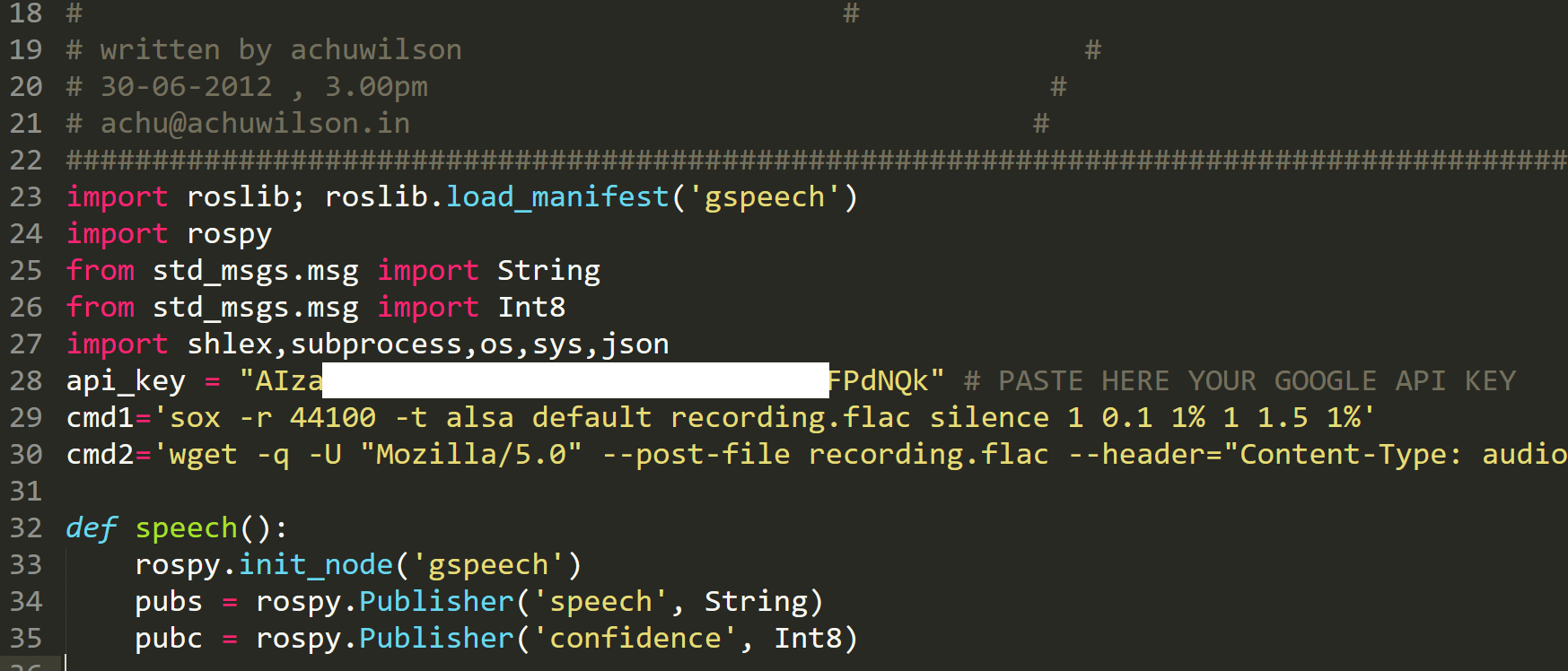
API keys were found using regex on the scraped data. I also looked into searching for high entropy strings but that resulted in too many false positives. The regex patterns were taken from https://github.com/l4yton/RegHex and https://github.com/odomojuli/RegExAPI. Some of the API regex’s are shown below, all are on my github.
So, have people put API keys on a public website? Yes. In total 231 repls contained API keys and emails that were captured by these regexes. 45 for Facebook, 44 for Mailto: emails (no creds), 44 for Twitter, 43 for AWS, 27 for Google, 11 for Mailgun and the rest only had a few each… ect.
I have looked at many of these repls I only see a few false positives. A couple of repls contain the same API keys because despite it being possible to use the same repl to save multiple versions e.g repl.it/GFlg and repl.it/GFlg/2 (now both 404) these people must not have known. Excluding false positives and duplicates there are 100-ish unique API keys. I hope these API keys have already been revoked or have since expired, however I know API keys tend not get revoked/expired and many will still be active. I have not checked to see if any are active.
There is definitely more information/creds to be discovered. For example I accidentally found a SQL servers IP, username, and password in one repl that also had Twitter API keys in.
How to reduce the risk
To stop the risk yourself don’t post API keys on the publicly accessible Internet, if you do revoke them. Also you can use test accounts, I can see from some of the Reddit usernames that the accounts were just created for the API key e.g they end with “_bot”.
If you operate a website, don’t use an incremental counter for anything that could possibly have personal data. Only allow OAuth, for some reason Reddit still allows the username and password to be part of the authorisation the result is if the user uploads their code online they could potentially lose their account. It is also common to not link an email to a Reddit account so recovery could also not be possible.
Final comments
I wanted to share my findings earlier but I waited until it was safer to do so. People did share their API keys on repl.it thinking they were safe but they were not.
Subscribe
Subscribe to this blog via RSS.
Recent Blog Posts
-
 Posted on 21 Nov 2020
Posted on 21 Nov 2020
-
 Posted on 19 Nov 2020
Posted on 19 Nov 2020
-
 Posted on 23 Jul 2020
Posted on 23 Jul 2020
-
 Posted on 06 May 2017
Posted on 06 May 2017
Recent Snippets
-
 Posted on 27 Mar 2017
Posted on 27 Mar 2017
-
Posted on 04 Mar 2017
-
 Posted on 23 Jan 2017
Posted on 23 Jan 2017
All Blog Posts and Snippets
Click here to view all blog and snippets.
Popular Tags
Adblock (2) Ethics (1) Adverts (2) Images (1) Formats (1) Zeronet (2) P2p (3) Dns (1) Zookos triangle (1) Data (2) Maths (1) Bitcoin (1) Blockchain (1) Svg (1) Python (2) Regex (2) Coding (2) Coding challenge (2) Repl.it (1) Emoji (2) Automation (2)